As we are building the online payment system and its adjacencies, we will share our approach to the Scaling methodology that we are using. While scaling out is the final frontier, we should be able to get the full capacity out of the smallest unit of deployment, optimize data access patterns, using of a caching layer to minimize database lookups and finally scale out elastically.

Application — Per VM Scalability
Blocking I/O
We were using the traditional thread per request model for our backend services. In this model, the scalability is limited by the number of threads that can be created. Also, most of the applications are I/O intensive and not CPU Intensive. Since scalability is limited to the number of threads and there is a cost involved in creating and scheduling the threads with an upper bound on the number of threads, this system cannot scale well.
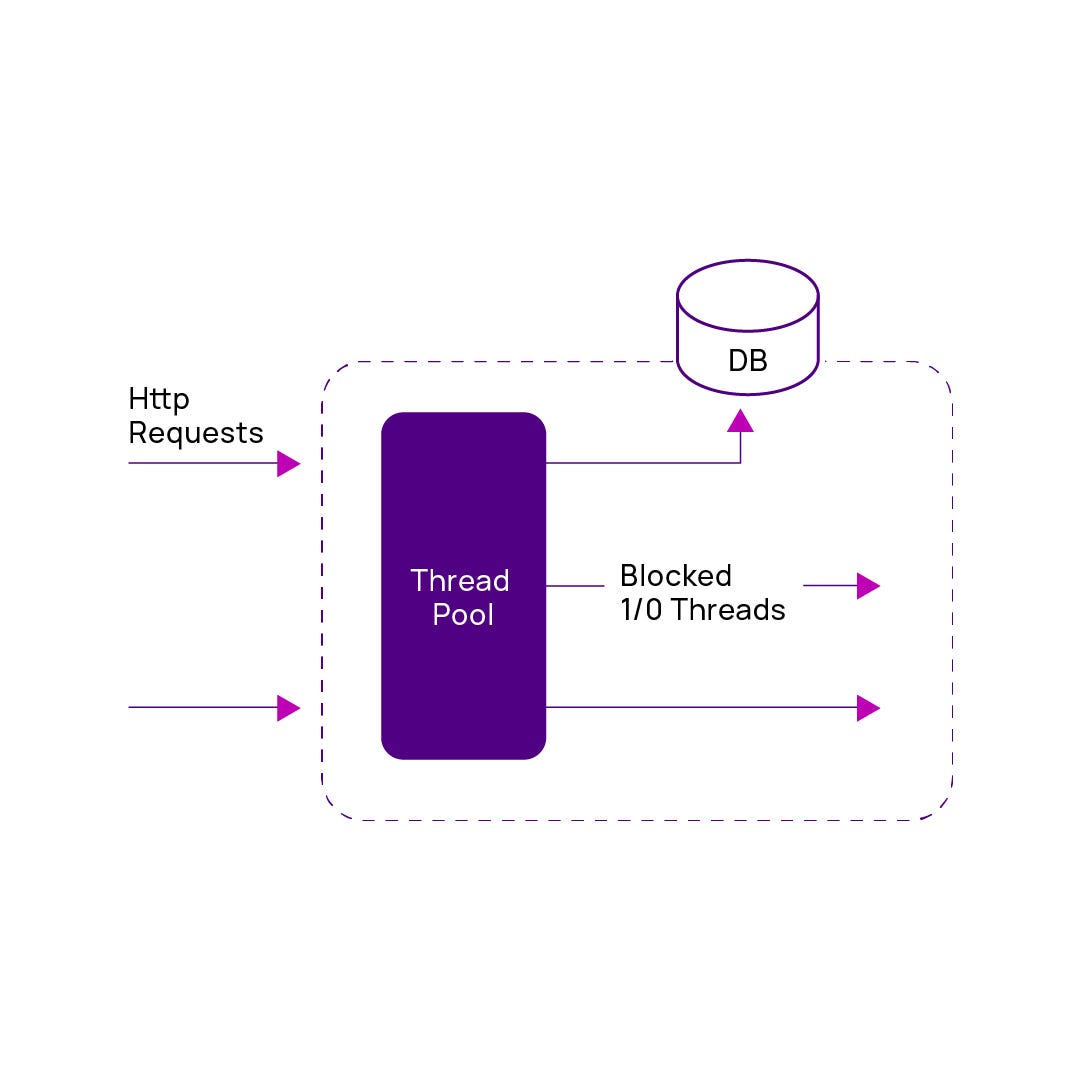
The only way forward with such application stacks is to do vertical scaling by increasing the memory footprint and system capacity and adding multiple copies of the suboptimal systems. In simple terms, throwing money at the problem. But this is not the age of such solutions where frugality is the key tenet.
Reactive & Non-Blocking I/O
We moved towards Non-Blocking I/O at the application level. This involves moving the application stack from the traditional blocking I/O to non-blocking I/O using event loops and reactive constructs. With Spring Web Flux as the framework and Netty as the application server, we adopted the reactive non-blocking model. In this model, threads are not blocked on I/O. It scales better than the traditional applications that use Blocking I/O. The HTTP clients (Spring Web Client) are also a type of non-blocking client and by using these the application stack becomes truly non-blocking (internally, not from the caller’s perspective).

Since the reactive JDBC drivers are not up for the broader adoption, we are still using the blocking JDBC at this point.
Data Reads & Writes
We adopted Command Query Responsibility Segregation (CQRS), where reads are separated from writes. The writes where the actual transactions are written to the database are separated from the bulk reads or queries on the data. This can be modelled as a strongly consistent vs eventually consistent and the database replication modelled around the same. We are using a strongly consistent pattern of replication at this point in time. We are also working on creating a reading scheme which is different structurally from the write schema. Write schema is optimized for transnationality and the same when overburdened for reads doesn’t scale well when reading data from multiple tables.

We are working on creating a separate schema for the reads where the data structure is optimized for the queries as below.
Caching
Write Through Caching is used.
Write to both cache and database simultaneously
Cached data accessed immediately
For Transactional data
Trailing transaction lookup
Example: Order / Purchase flows
Eager Loading for Metadata
Example: Merchant Configuration, Product Configuration
Scaling
We are currently using Z-axis scaling. Legacy monoliths are scaled using Z-axis scaling
Same code, different deployments to cater to different functionality
Functional breakdown of Monolith to Microservices and scaling out
Transitioning to Y-axis scaling
Refactored monoliths and new services are Containerized on the K8 platform for elastically scaling out the microservices.


Amrita Konaiagari is a Marketing Manager at Plural by Pine Labs and Editor of the Plural blog. She has over 10 years of marketing experience across Media & Tech industries and holds a Master’s degree in Communication and Journalism. She has a passion for home décor and is most definitely a dog person.